
[ 페이지 교체 (Page Replacement) ]
페이지를 쫓아내는 걸 Page Replacement라고 하며 OS가 하는 일이다. 이때 사용하는 알고리즘은 Replacement Algorithm이다.
비어있는 페이지가 없는 경우에는 어떤 페이지를 쫓아낸 후, 해당 메모리에 페이지를 올려야 한다.
가능하면 Page Fault가 일어나지 않고 되도록이면 메모리에서 직접 처리할 수 있도록 되어있다.
왜냐하면 페이지를 쫓아내고 난 후, 시간이 얼마 지나지 않아 그 페이지가 다시 참조가 되면 해당 페이지를 Swap area에서 메모리로 다시 올려야 한다.
이 과정은 시간이 매우 오래 걸린다.
어떤 페이지를 메모리에서 쫓아내고 그 자리에 어떤 페이지를 올려놓을 것인가를 결정해야 한다.
가능한 Page Fault가 일어나지 않고 되도록이면 메모리에서 직접 처리할 수 있게 해 줄수록 성능이 높아진다.
Reference String은 시간 순서에 따라서 페이지들이 참조된 순서를 나열해 놓은 것이다.
Reference String이 1,2,3,4,1,2,5,1,2,3,4,5라면 맨 처음에 첫 번째 페이지, 그다음 두 번째, 세 번째, 다시 첫 번째.. 순으로 참조되었다는 의미이다.
만약 1번 페이지가 사용이 됐다가 Swap Area로 쫓아내면 나중에 Page Fault가 나서 다시 Disk에서 Memory로 불러와야 하고,
1번 페이지를 메모리에서 쫓아내지 않았다면, Page Falut가 나지 않고 다시 메모리에서 참조될 수 있다.
✓ Free Frame이 없는 경우 Page Replacement
- 어떤 frame을 빼앗아 올지 결정해야 함
- 곧바로 사용되지 않을 page를 쫓아내는 것이 좋음
- 동일한 페이지가 여러 번 메모리에서 쫓겨났다가 다시 들어올 수 있음
✓ Replacement Algorithm
- Page-Fault Rate을 최소화 하는 것이 목표
- 알고리즘의 평가 : 주어진 Page Reference String에 대해 Page Fault를 얼마나 내는지 조사
- Reference String의 예 : 1,2,3,4,1,2,5,1,2,3,4,5
Victim Page가 결정되었으면 해당 페이지를 디스크로 쫓아낸다.
만약 디스크에서 메모리에 올라온 이후에 내용이 변경되었다고 하면 (Write가 발생했다면)
메모리에서 쫓아낼 때 변경된 내용을 Backing Store에 써줘야 하고, 내용 변경이 없다면 메모리에서 쫓아내기만 하면 된다.

Victim Page가 선정되어 쫓아내면 쫓겨난 페이지에 대한 테이블 Entry는 Invalid로 바꿔준다.
그리고 새로운 페이지를 메모리에 올리고 해당 페이지에 대해서는 Page Table Entry에 Frame 번호를 적어주고 Bit를 Valid로 변경해 준다.
이 역할을 운영체제가 하는 것이다.
● Optimal Algorithm
이 알고리즘은 알고리즘 중에서 Page Fault를 가장 적게 하는 알고리즘이다.
가장 먼 미래에 참조되는 Page를 교체한다. 하지만 실제 시스템에서는 미래를 알 수 없다.
현재 1번 페이지가 참조되었는데, 미래에 1번 페이지가 사용이 될지 안 될지 모르기 때문에 페이지를 쫓아내야 할지 말아야 할지 결정하기 어렵다.
이 알고리즘은 페이지의 사용을 미리 다 안다고 가정하며, 실제 시스템에서는 사용될 수 없다.
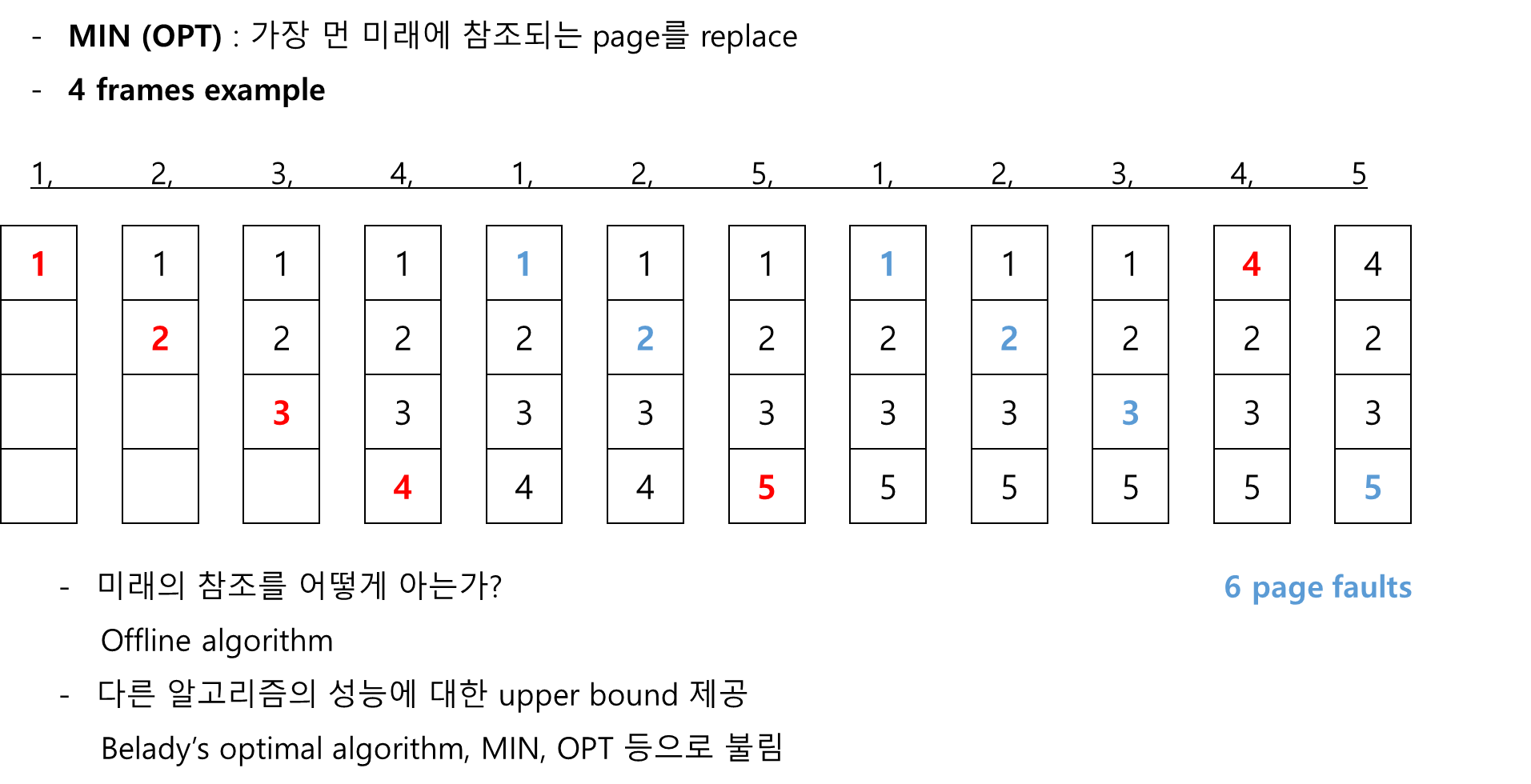
비어있는 메모리에 페이지들이 처음 올라갈 때에는 무조건 Page Fault가 난다.
페이지가 순차적으로 메모리에 올라가다가 다시 1번 페이지가 참조가 되면 (이미 메모리에 올라가 있기 때문에) 메모리에서 직접 참조가 된다.
그 후 나중에 5번 페이지의 요청이 왔을 때, 메모리에 올라가 있지 않으니 Page Fault가 발생하고 메모리에서 쫓아낼 페이지를 결정한다.
1번, 2번, 3번, 4번 페이지 중 쫓아낼 페이지를 정해야 하는데, 이때가장 먼 미래에 참조되는 페이지를 쫓아낸다.
4번 페이지가 가장 나중에 참조되기 때문에 5번을 메모리에 올려놓기 위해서 4번을 쫓아낸다.
이 알고리즘을 사용하는 경우에 총 여섯 번의 Page Fault가 발생한다.
어떤 알고리즘을 쓰더라도 Page Fault를 여섯 번보다 작게 나는 경우는 없다.
어쨌든 이 알고리즘은 미래를 다 안다고 가정하기 때문에 실제 시스템에서의 사용은 불가능하다.
하지만 실제 시스템에서 사용하는 다른 알고리즘에 대한 Upper Bound를 제공한다.
아무리 좋은 알고리즘을 만들어도 이 알고리즘보다 좋은 알고리즘은 만들 수 없다.
예를 들어, 알고리즘 하나를 만들었는데 이 알고리즘과 Optimal Algorithm이랑 비슷한 성능이 나왔다면 더 이상 좋은 알고리즘을 만들 수 없다는 뜻이다.
● FIFO (First In First out) algorithm
실제 시스템에서 사용 가능한 알고리즘이다. 미래를 모를 때 제일 참고할만한 단서는 과거를 보는 것이다.
FIFO 알고리즘은 먼저 들어온 Page를 내쫓는 방법이다.
메모리의 크기를 늘려주면 보통 성능이 좋아지는데 이 알고리즘은 메모리 크기를 늘려주면 오히려 성능이 더 안 좋아지는 현상이 나타난다.
앞에서 본 Reference에 대해서 Frame이 세 개일 때랑 네 개일 때를 비교해 보자.
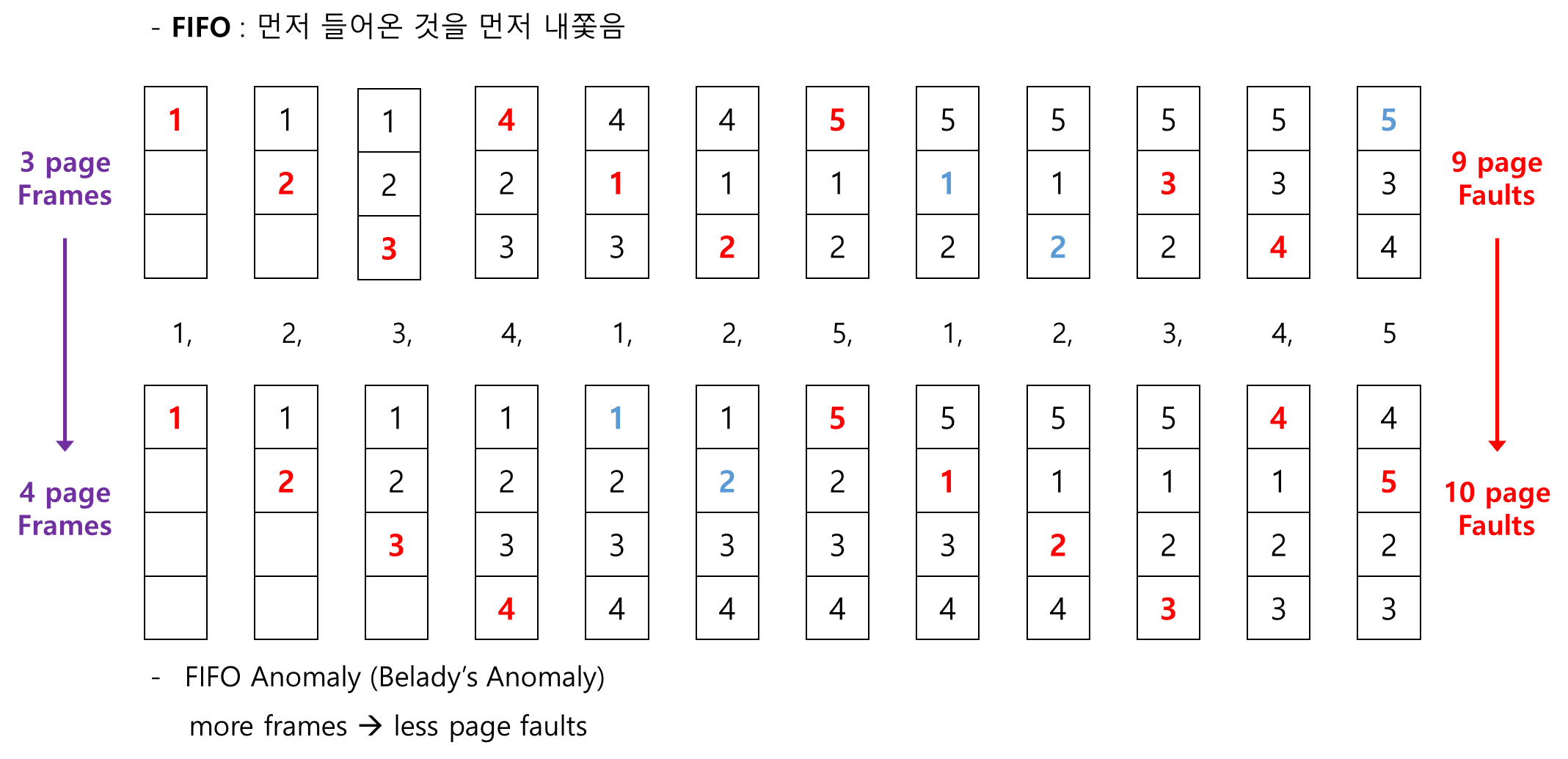
Page Frame이 세 개 있을 때 보다 네 개 있을 때 Page Fault가 더 많이 나는 것을 볼 수 있다.
● LRU(Least Recently Used) Algorithm
가장 오래전에 참조된 Page를 쫓아내는 알고리즘이다.
FIFO는 먼저 들어온 Page를 먼저 쫓아냈지만 LRU 알고리즘은 가장 오래전에 사용된 Page를 먼저 쫓아낸다.
들어온 기준이 아니라 사용된 시점을 기준으로 하기 때문에 가장 먼저 들어왔지만 들어와서 재사용이 되었으면 쫓아내지 않는다.
최근에 참조된 페이지가 다시 참조될 경향이 높으므로 비교적 Page Fault를 줄일 수 있다.

● LFU (Least Frequently Used) Algorithm
가장 덜 빈번하게 참조된 페이지를 쫓아내는 방법이다.
참조 횟수가 제일 적은 페이지를 메모리에서 쫓아내며 과거에 참조 횟수가 많았던 Page는 미래에도 참조될 가능성이 높으니 쫓아내지 않는 것이다.
참조 횟수가 적은 페이지가 여럿 있으면 아무거나 쫓아내지만 성능을 좀 더 향상하고 싶을 경우,
동률인 Page 중에서 마지막 참조 시점이 더 오래된 페이지를 쫓아낸다.
✓ LFU
- 참조 횟수 (reference count)가 가장 적은 페이지를 지운다.
- - 최저 참조 횟수인 page가 여러 page 중 임의로 선정한다.
- - 성능 향상을 위해 가장 오래전에 참조된 page를 지우게 구현할 수도 있다.
✓ 장단점
- LRU처럼 직전 참조 시점만 보는 것이 아니라 장기적인시간 규모를 보기 때문에 page의 인기도를 좀 더 정확히 반영할 수 있다.
- 참조 시점의 최근성을 반영하지 못한다.
- LRU보다 구현이 복잡하다.
● LRU와 LFU 알고리즘 예제
아래의 그림으로 LRU와 LFU 알고리즘을 비교해 보자.

페이지 프레임은 네 개이며, 시간순으로 1번이 네 번, 2번은 두 번, 3번은 두 번 참조 후 다시 2번 페이지가 한 번 참조되며 마지막에 4번 페이지가 참조된다.
현재 시각에는 5번 페이지가 참조되어야 하기 때문에 하나의 페이지를 쫓아내야 한다.
이 경우에서 LRU 알고리즘은 1번 페이지를 쫓아내며, LFU는 4번 페이지를 쫓아낸다.
LRU 알고리즘은 이전 기록을 생각하지 않기 때문에 가장 오래전에 참조되기는 했지만 과거에 많은 참조가 있었다는 점을 고려하지 않는 문제점이 있다.
LFU 알고리즘은 4번 페이지를 쫓아냈는데 비록 참조 횟수가 한 번이지만 이제 막 여러 번의 참조가 시작되는 상황이라면 문제가 생길 수 있다.
● LRU와 LFU 알고리즘의 구현

LRU 알고리즘은 메모링 안에 있는 Page들을 참조 시간에 따라서 줄을 세운다.
맨 위에 있는 페이지가 가장 오래전에 참조된 Page이며, 아래에 있을수록 가장 최근에 참조된 Page이다.
Linked List로 Page 참조 시간을 관리한다.
만약 어떤 페이지가 메모리에 올라오거나 메모리 안에서 다시 참조되면 그 Page는 다시 맨 아래로 가며, 쫓아낼 때에는 맨 위에 있는 Page를 쫓아낸다.
이렇게 List 형태로 구현하면 시간 복잡도가 O(1)이 된다.
페이지가 참조될 때마다 시간을 기록해 놓고 가장 오래된 페이지를 쫓아낼지 결정하는 경우, 시간 복잡도가 O(n)으로 굉장히 비효율적으로 된다.
LFU 알고리즘은 참조 횟수가 가장 적은 Page가 맨 위에 있고, 밑으로 갈수록 참조 횟수가 많은 페이지이다.
쫓아낼 때에는 LRU 알고리즘과 마찬가지로 맨 위 Page를 내쫓는다.
LRU 알고리즘은 시간 순서로 따지기 때문에 한 번만 참조되어도 제일 아래로 내려올 수 있지만,
LFU 알고리즘은 참조 횟수가 1 늘어났을 뿐, 그렇다고 맨 아래로 내려가지 못하고 한 단계씩 비교하면서 내려가야 한다.
O(n)의 시간 복잡도가 생기기 때문에 LFU 알고리즘은 Heap으로 구현된다. 그렇게 되면 O(logn)이 구현 가능하다.

자식이 두 개씩 있는 이진트리의 형태이다.
맨 위는 참조 횟수가 가장 적은 페이지를 놓고 밑으로 갈수록 참조 횟수가 많은 페이지를 놓는다.
참조 횟수가 1이 늘어나면 직계 자식들과 비교해서 해당하는 경로만 따라 밑으로 내려가면서 내가 어디까지 내려갈 수 있는지를 찾는다.
이진트리의 높이는 log2n이며, 쫓아낼 때에는 Root에 있는 Page를 쫓아내고 Heap을 재구성한다.