
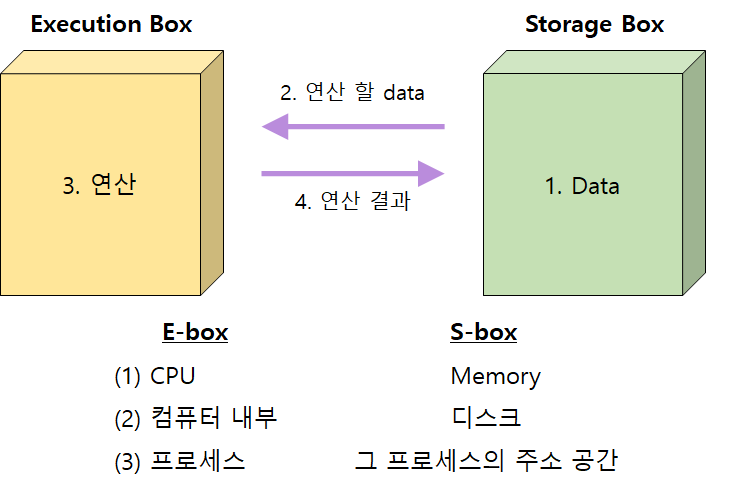
● 데이터의 접근
데이터는 Storage Box에 저장되어 있고 그 데이터를 가지고 Execution Box 위치에서 연산 작업을 한 후 다시 원래 위치인 Storage Box에 저장한다. 이렇게 데이터를 읽고 연산/수정 후 결과를 다시 저장하는 과정에서 누가 먼저 읽어갔느냐에 따라 결과가 달라질 수 있다.
● Race Condition
Storage Box를 공유하는 Execution Box가 여러 개 있을 경우 Race Condition의 가능성이 있다. Storage Box는 Memory Address Spage라고 하고 Execution Box는 CPU Process라고 생각해 보자.
Race Condition가 발생하게 되면 운영체제 커널과 관련된 문제가 제일 크다. 프로세스가 운영체제에게 System Call을 하면 운영체제 커널이 해당 프로세스를 대신하여 코드를 실행한다.
이 과정에서 커널에 있는 데이터에 접근을 하게 되는데 Timer Interrupt가 발생해 CPU를 뺏긴 후, 또 다른 프로세스가 실행 중에 System Call을 해서 커널 코드에 접근했을 때 문제가 발생할 수 있다.
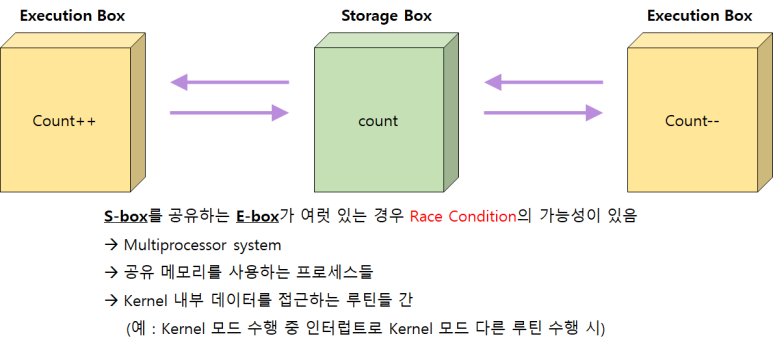
즉, 커널 코드가 실행 중에 인터럽트가 발생해 인터럽트를 처리하는 코드를 실행할 텐데, 그것도 커널 코드이기 때문에 커널의 데이터를 건드렸을 때 문제가 발생할 수 있다.
커널의 데이터는 여러 프로세스들이 공용으로 사용할 수 있기 때문이다.
OS에서 race condition은 언제 발생하는가?
- Kernel 수행 중 인터럽트 발생 시
- Process가 system call을 하여 kernel mode로 수행 중인데 context switch가 일어나는 경우
- Multiprocessor에서 shared memory내의 kernel data
[1] Kernel 수행 중 인터럽트 발생 시
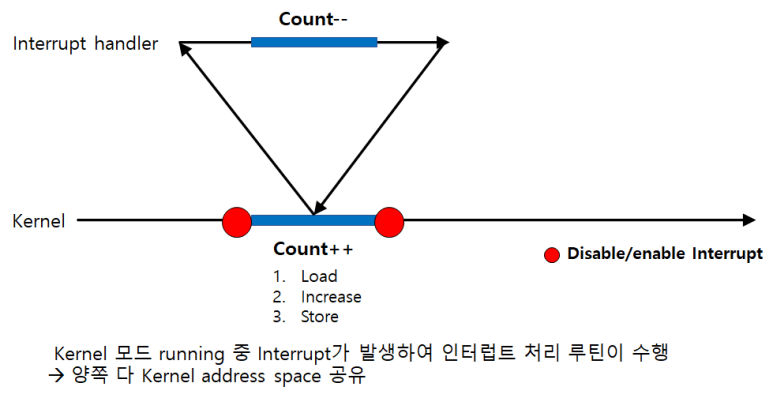
커널이 Count라는 변수 값을 1 증가시키고 있다고 하자. 보통 고급 언어로 된 Count++ 같은 문장은 CPU 내부에서는 여러 개의 Instruction을 통해서 실행한다.
Count라는 메모리 변수 값을 1 증가시킨다고 하면 메모리에 있는 변수 값을 CPU안에 있는 레지스터로 불러들이고 그 레지스터 값을 1 증가시킨 후, 레지스터의 값을 다시 메모리의 변수 위치에 갖다 쓴다.
그런데 이 변수를 CPU로 읽어 들인 상태에서 인터럽트가 들어왔을 경우에 하던 작업을 잠시 멈추고 인터럽트 처리 루틴으로 넘어가게 된다.
해당 루틴은 커널의 Data인 Count라는 변수를 1을 빼고 인터럽트 처리가 다 끝나면 원래 상태로 돌아온다.
(Context를 저장할 때, 메모리 Load 하는 라인까지 실행했으니 1을 증가시키고 저장하면 됨)
1 증가시키고 1 감소시켰으니까 Count라는 변수 값은 원래의 값과 동일해야 하는데 결과적으로는 1 감소는 적용이 되지 않고 1 증가한 것만 반영이 된다.
커널이 변수의 값을 이미 읽어 들였기 때문에 인터럽트 핸들러가 데이터 처리를 한 후, 저장되어있는 Context 위치로 되돌아왔을 때에는 이미 읽어 들인 변수에다 1을 증가시켜 주고 저장하기 때문이다.
→ 이렇게 중요한 변수 값을 건드리는 동안에는 인터럽트가 들어와도 인터럽트 처리 루틴으로 넘기는 게 아니라 해당 작업이 끝날 동안 인터럽트 실행을 하지 않게 한다. (Interrupt Disable)
[2] Process가 system call을 하여 kernel mode로 수행 중인데 context switch가 일어나는 경우
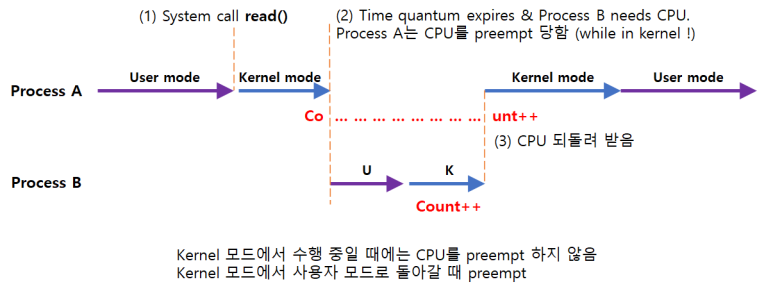
프로그램은 유저모드와 커널모드를 번갈아가면서 실행을 하는데 이때, CPU가 독점적으로 사용하는 게 아니라 할당 시간이 있고 정해진 할당 시간이 끝나면 CPU를 반납하게 된다.
프로세스 A는 할당 시간이 끝나서 프로세스 B로 넘어갔다가 B의 할당 시간이 끝나면 CPU 제어권은 다시 프로세스 A로 넘어간다.
유저 모드에서 할당 시간이 끝나 Context Switching이 발생하면 상관이 없다. 하지만 System Call을 통해 커널의 코드가 실행 중이고 커널의 코드가 실행하면서 커널에 있는 데이터인 Count라는 변수를 건드렸을 때에는 문제가 발생할 수 있다.
커널의 데이터인 Count라는 변수의 값을 1 증가시키고 있는 도중에 할당 시간이 끝나 CPU가 프로세스 B로 넘어간 후, B가 유저레벨 코드를 실행하다가 System Call을 통해 커널에서 Count라는 변수를 건드렸다고 해보자.
그러다가 할당 시간이 끝나서 다시 A로 돌아가는데 프로세스 A는 Count 변수 값을 (1 증가시키려고) CPU안으로 읽어 들인 그다음 시점부터 Instruction을 실행한다.
프로세스 B가 Count값을 증가시키기 전에 Count값을 읽었고, CPU를 다시 얻었을 때에는 그 시점에 Context를 가지고 Count 값을 1 증가시킨 후 저장을 했다. 이러한 이유로 인해 프로세스 A에서도 Count를 1 증가시키고 프로세스 B에서도 1 증가시켜, 총 2가 증가되어야 하는데 B에서 증가시킨 건 반영이 되지 않는다.
→ 어떤 프로세스가 커널 모드에 있을 때에는 할당 시간이 끝나도 CPU 제어권을 뺏기지 않도록 한다.
할당 시간은 끝났지만 커널 모드가 끝나고 유저 모드로 들어갈 때 CPU를 넘겨주도록 한다. 할당 시간이 정확하게 지켜지지 않고 약간의 오차가 생길 수 있지만, Time Sharing 시스템에서는 Real-time System이 아니라 조금 시간이 더 지났다고 해서 시스템에 큰 문제가 생기지 않는다.
[3] Multiprocessor에서 shared memory내의 kernel data
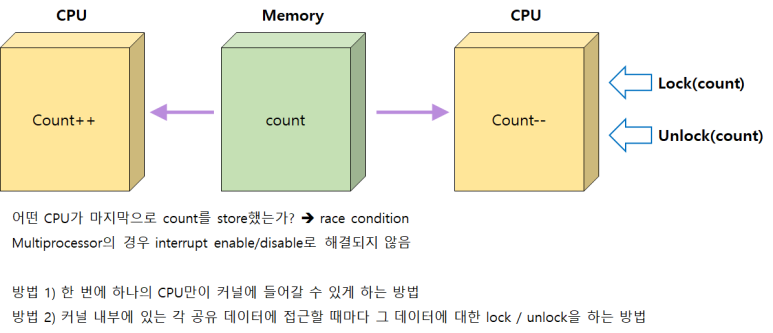
마지막으로 Multi-Processor 환경에서 살펴보자. 1번 CPU에서 데이터를 읽어서 수정할 때, 인터럽트를 막는다고 2번 CPU가 데이터에 접근하지 못할 이유가 없다.
이 경우에는 어떤 프로세스가 공유 데이터를 건드리는 동안에는 인터럽트를 막아서 해결되는 문제가 아니다. 한 번에 한 CPU만 커널에 진입할 수 있도록 하는 방법이 있긴 하지만, 만약 두 프로세서가 서로 다른 데이터에 접근하여 Race condition의 가능성이 없음에도 불구하고 한 번에 한 CPU만 커널에 들어가게 되면 비효율적이다.
CPU가 하나일 경우(싱글 프로세서), 작업하는 도중에 CPU 제어권이 넘어가서 생기는 문제였고 지금의 예시는 근본적으로 작업 주체가 여럿이기 때문에 발생하는 문제이다.
→ 해당 데이터에 접근할 때 lock을 걸어야 한다. 1번 CPU가 데이터를 Load 하기 전에 Lock을 걸어서 다른 CPU가 이 데이터에 접근하지 못하게 한 다음 데이터를 변경하고 저장이 끝나고 나면 Unlock을 해줘서 다른 CPU가 그 데이터에 접근할 수 있게 한다.
[ 이전 발행 글 ]
2022.12.26 - [Operating System] - [운영체제] CPU 스케줄링 1 (CPU burst Time, Scheduler & Dispatcher)
[운영체제] CPU 스케줄링 1 (CPU burst Time, Scheduler & Dispatcher)
● CPU and I/O burst in program Excution 프로그램 실행이 되면 프로그램은 아래와 같은 Path를 실행한다. 프로세스는 CPU에서 기계어가 실행되는 상태와 I/O 작업을 하는 상태의 반복이다. 프로그램마다 다
rannnneey.tistory.com
[운영체제] CPU 스케줄링 2 (FCFS, SJF, SRTF, Round Robin, Multilevel Queue, Multilevel Feedback )
● Scheduling Algorithms 종류 FCFS (First-Come First-Served) SJF (Shortest-Job-First), SRTF (Shortest-Remaining-Time-First) Priority Scheduling RR (Round Robin, 라운드 로빈) Multilevel Queue Multilevel Feedback Queue 스케줄링 알고리즘은
rannnneey.tistory.com
[운영체제] CPU 스케줄링3 (Multiple-Processor, Real-Tme, Thread, Algorithm 평가)
이전 발행글 2022.12.26 - [Operating System] - [운영체제] CPU 스케줄링 1 (CPU burst Time, Scheduler & Dispatcher) [운영체제] CPU 스케줄링 1 (CPU burst Time, Scheduler & Dispatcher) ● CPU and I/O burst in program Excution 프로그램
rannnneey.tistory.com