
파일 시스템 종류
파일시스템은 저장매체나 운영체제에 따라 사용이 제한되며, 아래와 같은 종류가 있다.
- exFAT : USB에 자주 사용되는 파일 시스템 (File Allocation Table)
- NTFS : 윈도우 운영체제에서 사용되는 파일 시스템 (New Technology File System)
- ext, ext2, ext3, ext4, xfs : 리눅스 운영체제에서 사용되는 파일 시스템 (Extended File System)
UNIX 파일 시스템
아래의 구조는 가장 기본적인 파일 시스템 구조이며, 이 구조로부터 발전하면서 FAT, Ext 등등이 생겨났다.
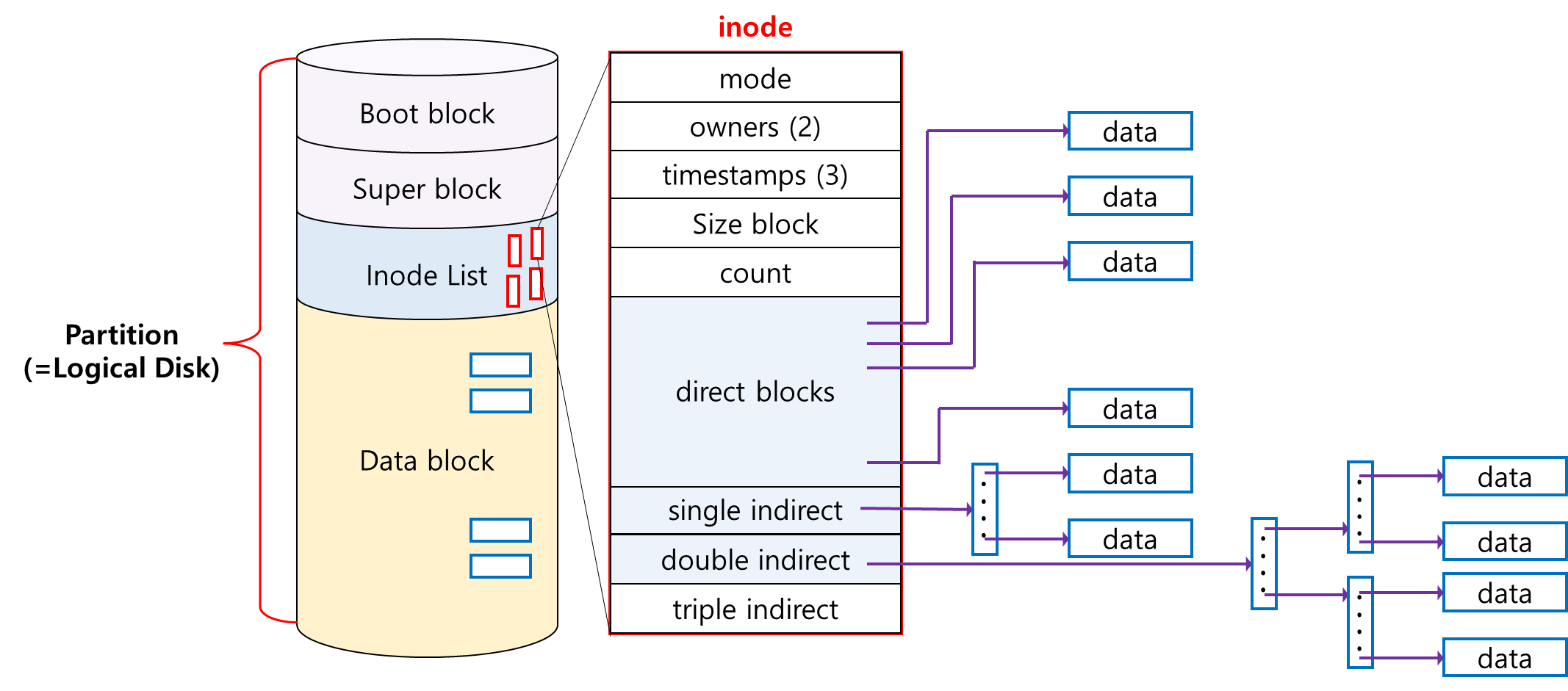
하나의 논리적 디스크에 파일 시스템을 설치해 놓으며, Boot, Super, Inode, Data block 순서대로 저장이 된다.
Boot Block
Boot Block은 어떤 파일 시스템이든 가장 맨 처음에 위치해 있다.
컴퓨터에 어떤 파일 시스템이 저장되어 있는지 모르기 때문에 Bootstrap Loader는 0번 블록을 메모리에 올린다.
부팅에 필요한 기본 정보가 0번 블록에 저장이 되며, 운영체제 커널의 위치가 어디에 있는지를 찾아 메모리에 올려 부팅이 이루어지도록 한다.
Super Block
Super block은 이 파일 시스템에 관한 총제척인 정보를 담고 있다.
어떤 블록이 빈 블록인지, 어떤 블록이 사용 중인지, 어떤 블록에 실제 파일이 저장되는지를 총체적으로 관리해 준다.
Inode (Index node)
파일의 메타데이터는 그 파일을 갖고 있는 Directory에 가면 기록되어 있다.
그런데 실제 파일 시스템에서는 Directory가 메타데이터를 다 갖고 있지는 않다.
Directory는 메타데이터의 일부분만 가지고 있으며, 실제 파일의 메타데이터는 아이노드 리스트라는 별도의 위치에 보관하고 있다.
Directory는 파일들의 이름과 inode 번호를 갖고 있으며, 나머지 메타데이터(파일의 소유주, 접근권한, 최종 수정 시간 등)는 inode에 저장되어 있다.
Directory 밑에 있는 파일의 아이노드 번호가 10번이라고 할 때, 아이노드 리스트의 10번에 가면 해당 메타데이터가 저장이 되어 있다.
유닉스는 Direct Index, Single Indirect, Double Indirect, Triple Indirect 네 가지로 파일의 위치 정보를 구성한다.
파일의 크기가 작으면 Direct Index 포인터로만 그 파일의 위치를 표현할 수 있지만, 큰 파일의 경우 Indirect를 이용해야 한다.
FAT(File Allocation Table) File System
윈도우나 모바일에서 사용하는 파일 시스템의 구조는 Boot Block, FAT, Root Directory, Data Block이 있다.
FAT 파일 시스템에서 메타데이터 중 위치 정보는 FAT에서 보관하고 나머지 메타데이터는 Directory File이 갖고 있다.
FAT 파일 시스템에서는 파일의 이름을 비롯한 접근 권한, 사이즈, 소유주 등 모든 정보를 Directory에 저장되어 있다.
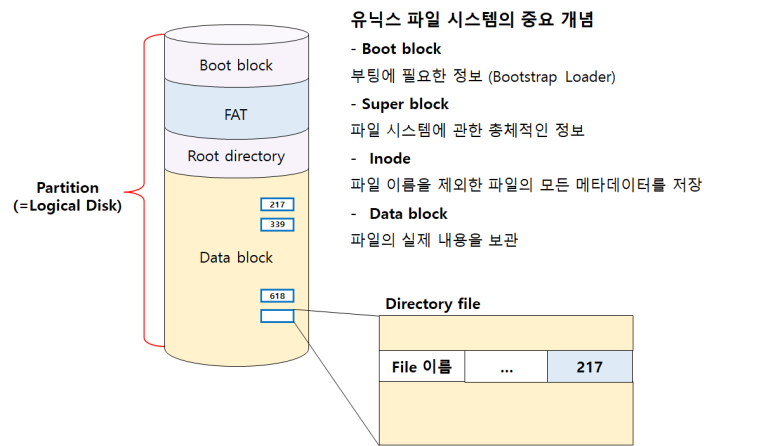
FAT이라는 별도의 배열이 있는데, 이 배열의 크기는 디스크가 관리하고 있는 Data block의 개수와 같다.
해당 배열에는 그다음 블록이 어디 있는지에 대한 정보를 담고 있다.
첫 번째 블록의 위치는 217번지라면, 두 번째 블록을 알기 위해서 FAT의 217번 Entry를 확인하면 다음 블록의 위치를 알 수 있다.
해당 위치에 618이라고 적혀있으니, 그 파일의 두 번째 블록은 618번지에 있다는 걸 알 수 있다.
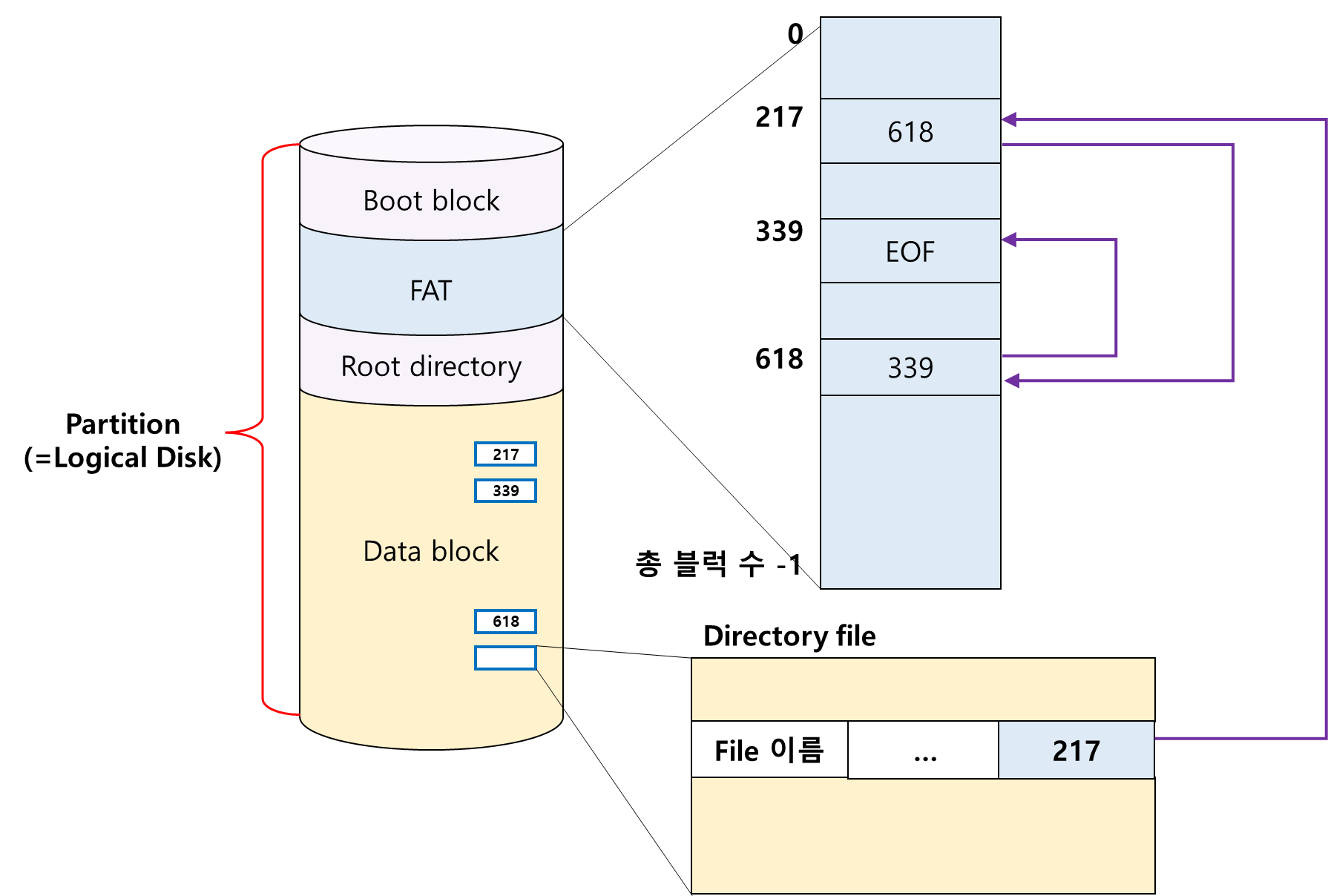
Linked Allocation을 활용한 것인데 실제 블록에 접근하는 게 아니라 FAT만 확인하여 직접 접근이 가능하다.
또한, Bad Sector가 발생하더라도 FAT과 Data block은 분리되어 있기 때문에 문제가 생기지 않는다.
FAT은 매우 중요한 정보이기 때문에 보통 두 Copy 이상을 저장하고 있으며 Linked Allocation을 변형한 방법이다.
Free-space Mangement
● Free-space Management : 비어있는 블록을 어떻게 관리할 것인가?
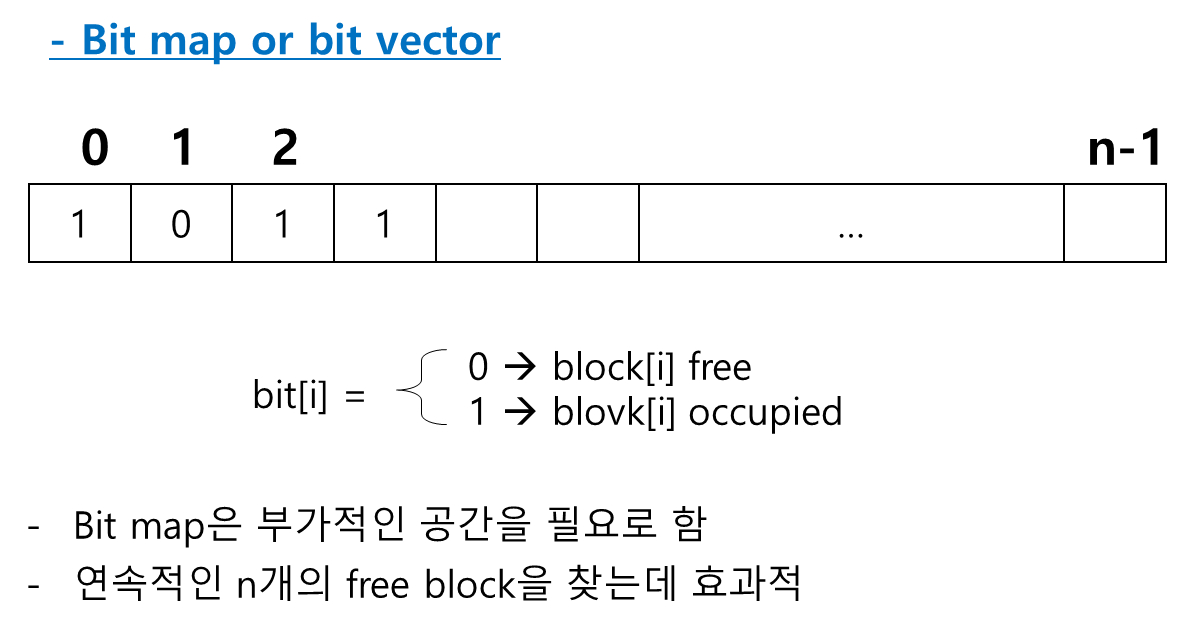
- Bit Map
- Linked List
- Grouping
- Counting
Bit Map
유닉스의 경우 Super Block에 Bit의 배열을 두고 첫 번째 블록이 비어있는지 사용되어 있는지를 0과 1로 나타낸다.
Bit Map의 크기는 Data block의 개수만큼 구성이 되어 있으며, 파일이 새로 만들어지거나 파일의 크기가 커지게 되면 비어있는 블록 중에 하나를 할당해야 한다.
할당되면 1로 표시를 하고 삭제되면 1로 표시되어 있던 값을 0으로 표시한다.
이러한 관리를 파일 시스템이 관리하고 있으며 블록 하나당 1bit로, 디스크에 많은 공간을 차지하지는 않지만 부가적인 공간을 필요로 한다.
디스크 헤드를 최대한 적게 이동하여 많은 양을 읽어오는 것이 시간적으로 효과적이므로 파일은 가능한 연속 할당을 해주면 좋다.
이러한 방식은 연속적인 빈 블록을 찾는데 효과적이다.
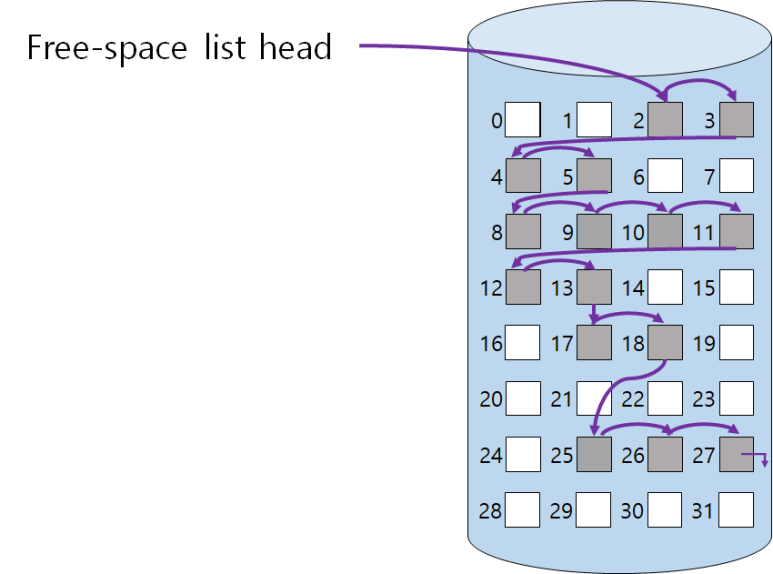
Linked List
비어있는 블록들을 연결하는 방식이다.
비어있는 블록의 첫 번째 위치만 포인터로 갖고 있고, 그다음 빈 블록의 위치는 포인터로 관리한다.
Bit Map에 비해 추가적인 공간 낭비는 없으나, 연속적인 빈 공간을 찾기 위해서는 디스크 헤드가 seek으로 따라가야 하므로 실제로 사용하기 어렵다.
Grouping
처음 비어있는 블록의 위치가 인덱스 역할을 하며, 첫 번째 빈 위치에 가면 비어있는 블록들의 포인터들이 저장된다.
마지막 포인터는 또 다른 인덱스를 가리킨다. (인덱스 할당과 비슷)
비어있는 블록을 한꺼번에 찾기에는 Linked List보다 효율적이지만 그래도 여전히 효과적인 방식은 아니다.
연속적으로 비어있는 블록을 찾기 위해서는 Counting 방식이 효과적이다.

예를 들어, 3, 4, 5, 6, 9, 10, 11, 12, 13, 14번 블록이 비어있고 나머지 블록은 할당되어 있는 16개의 블록을 생각해 보자.
n을 3으로 고려한 그룹화 방법을 적용하면 블록 3은 블록 4, 블록 5, 블록 6의 주소를 저장한다.
마찬가지로 블록 6은 블록 9, 블록 10, 블록 11의 주소를 저장한다. 블록 11은 블록 12, 블록 13, 블록 14의 주소를 저장한다.
Counting
연속적인 빈 블록을 표시하기 위해서 첫 번째의 빈 블록과 연속적으로 비어있는 블록의 개수를 쌍으로 관리한다.
이 방식은 여러 개의 연속된 블록이 동시에 할당하거나 해제할 수 있다.
